Many audio and video interviews are very long and unstructured, and not easily usable as research data. A team from CLARIN’s Czech node recently presented their state-of-the-art system that uses speech recognition and other natural language processing ( ) technologies designed specifically for oral history archives. The technology aims to make oral history data more accessible to researchers as well as the general public, opening up the wide range of audio material that is available in archives across the globe.
Called ‘Semantic Search – Asking Questions’, this new machine learning technology enables users to easily access oral history archives and engage with them in an intuitive and interactive way. The technology makes it possible to navigate long sequences of oral recordings by providing pre-generated, time-stamped questions that guide users through the content. In addition, a specialised search function enables direct interaction with the content in the video.

'Asking Questions Framework'
Methodology
The entire software is based on neural networks. All steps regarding audio and text handling are processed offline on a back-end Python server that also takes care of the metadata for the videos. The speech processing technology involves special, tailored speech-to-text speech recognition, search methods (terms and phrases), speech understanding methods (named entities, segmentation) and automatic subtitling, making it useful for a wide range of archives and disciplines.
The team decided against using OpenAI’s Whisper for transcribing the testimonies. First, to ensure that their technology is suited to the specificities of the Holocaust testimonies: the recorded speakers are relatively old, are not native speakers, and use words and a register that differs from today’s generic data from the web. Often, the testimonies are emotional. Combined, this makes it quite a different task for speech recognition, so the researchers designed the speech recogniser specifically for oral histories, retraining their system from scratch.
Semantic Search Feature
The team then added further features to improve the accessibility of the videos in the form of a semantic search. This powerful addition to search interfaces allows the user to search not for specific words or phrases, but for passages with a meaning related to a search phrase. Users can type in a question, which is sent to the backend server, which finds the 20 closest pre-generated questions and presents these to the user. Using a semantic search significantly increases the chance of finding relevant information, as queries are not limited to a single keyword.
The semantic search function was then expanded to also enable speech queries, meaning that users can ‘interact’ with the person in the video. The speech is recognised by the team’s in-house technology Speechcloud (automatic speech recognition module based on Wav2Vec 2.0 technology). Originally developed for English, it is now also possible to ask questions in Czech. The recognised utterance is automatically translated in real time into English using the LINDAT translator . The process of finding the closest match in the pre-generated questions is the same as before; the answers are the original audio track of the interview.
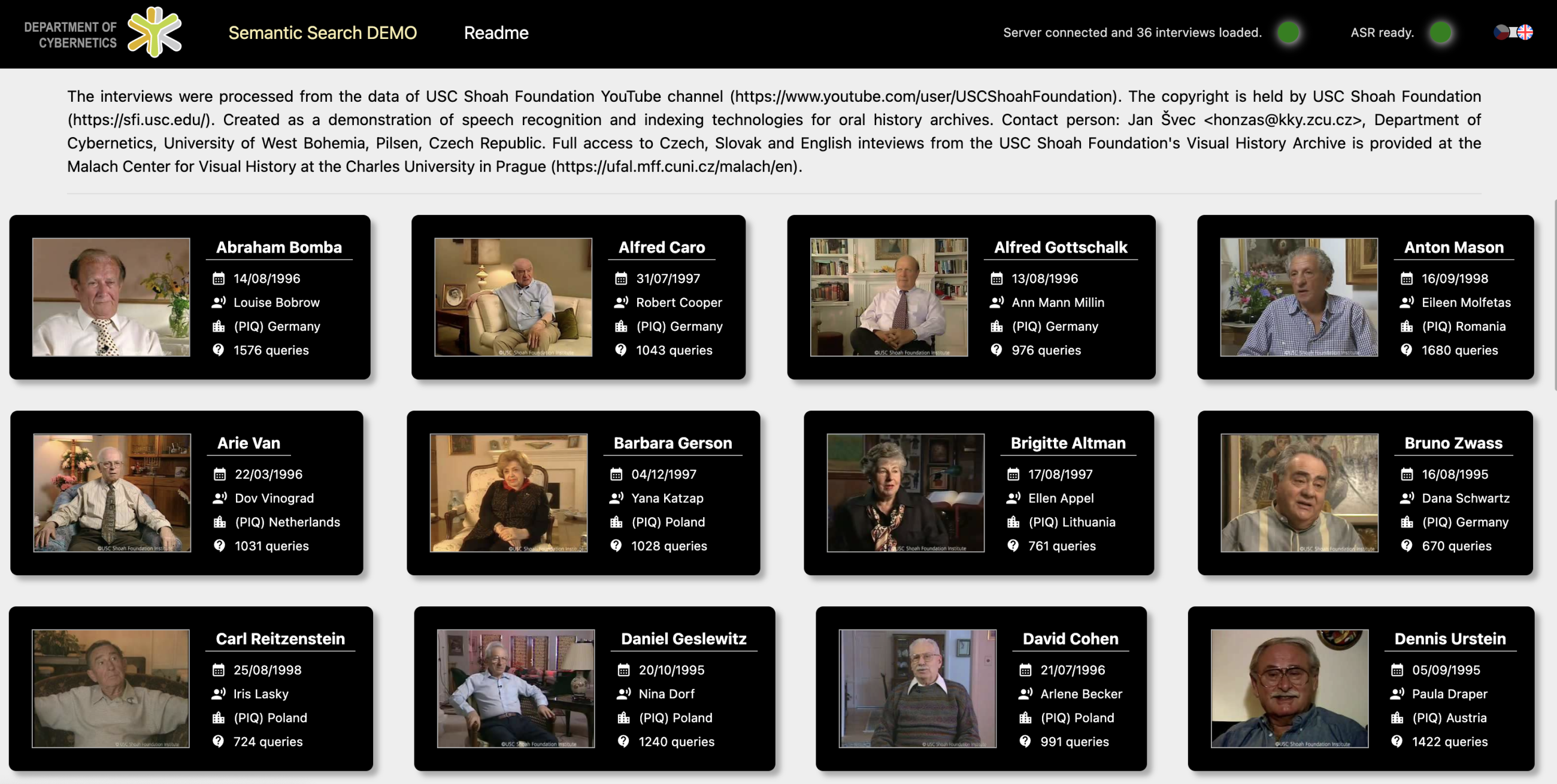
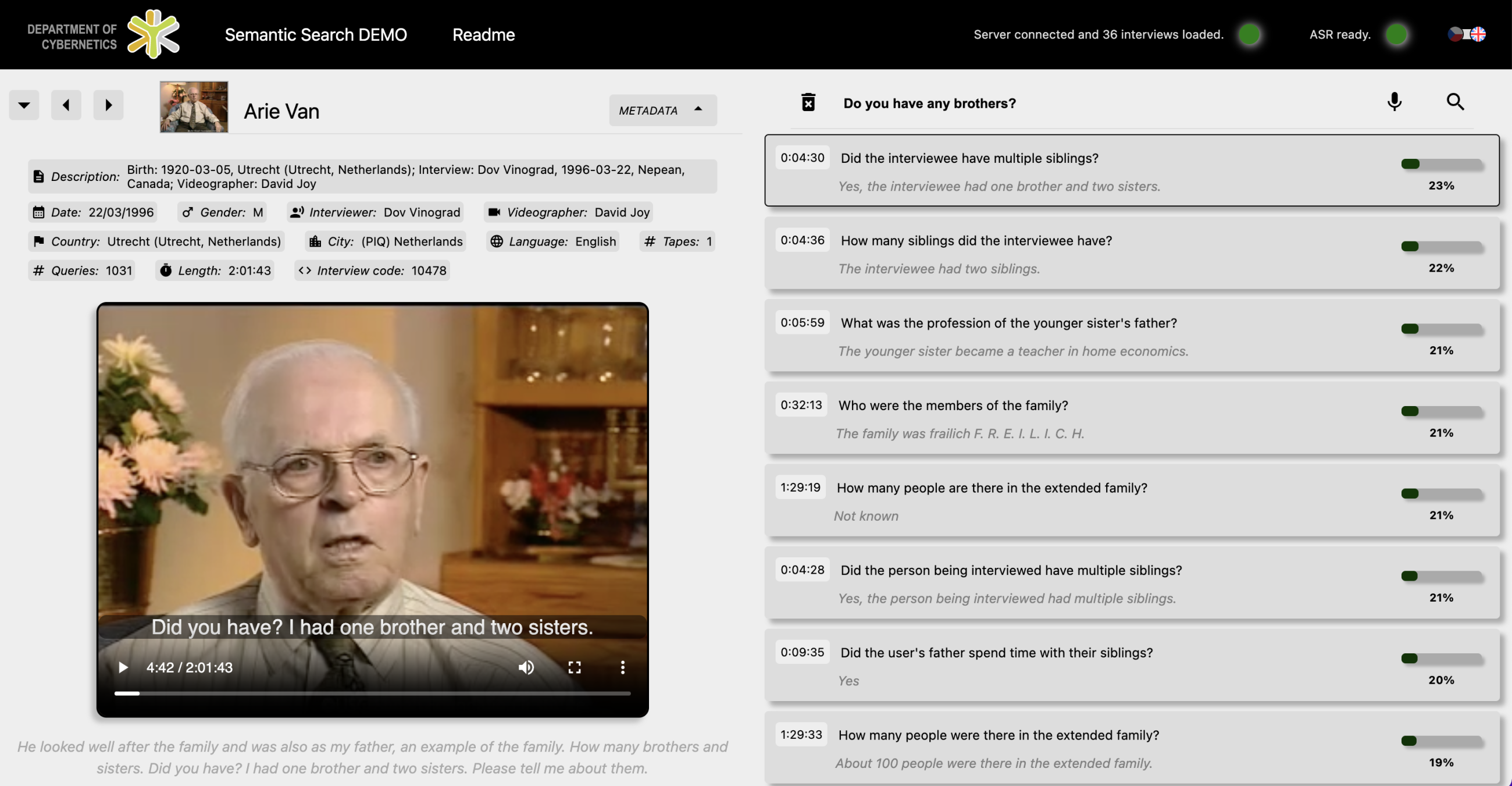
The main page of the application contains 36 interviews taken from USC Shoah Foundation videos on YouTube. After selecting a video, users see the video and metadata on the left of the screen, and all generated questions, with brief answers, on the right, along with continuity scores and timestamps. By clicking on the question, the video automatically plays from the required time stamp. This video outlines the main features of the application.
EHRI-CLARIN Workshop ‘Making Holocaust Oral Testimonies More Usable as Research Data’
