Language Resources and AI
In her recent talk at ESFRI’s 20th Anniversary Conference, linguist Kaja Dobrovoljc underlined the importance of open language resources for scientific advances, especially in the field of Artificial Intelligence (AI). In her presentation, she highlighted CLARIN’s important contribution to the development of everyday applications that need to make sense of the language we use, such as search engines, machine translation and voice assistants.
She adds: ‘In the era of ever-growing need for language data, especially in the multilingual European context, CLARIN represents a crucial pivot point for numerous stakeholders, not only as a platform for sustainable language data archiving, but also as a knowledge hub that helps researchers from various backgrounds navigate this complex interdisciplinary field.’ She notes that this role is likely to strengthen in the future, and hopes to see an even higher degree of cross-national exchange of services and tools in order to maximise their reusability.
Experience with CLARIN
Projects
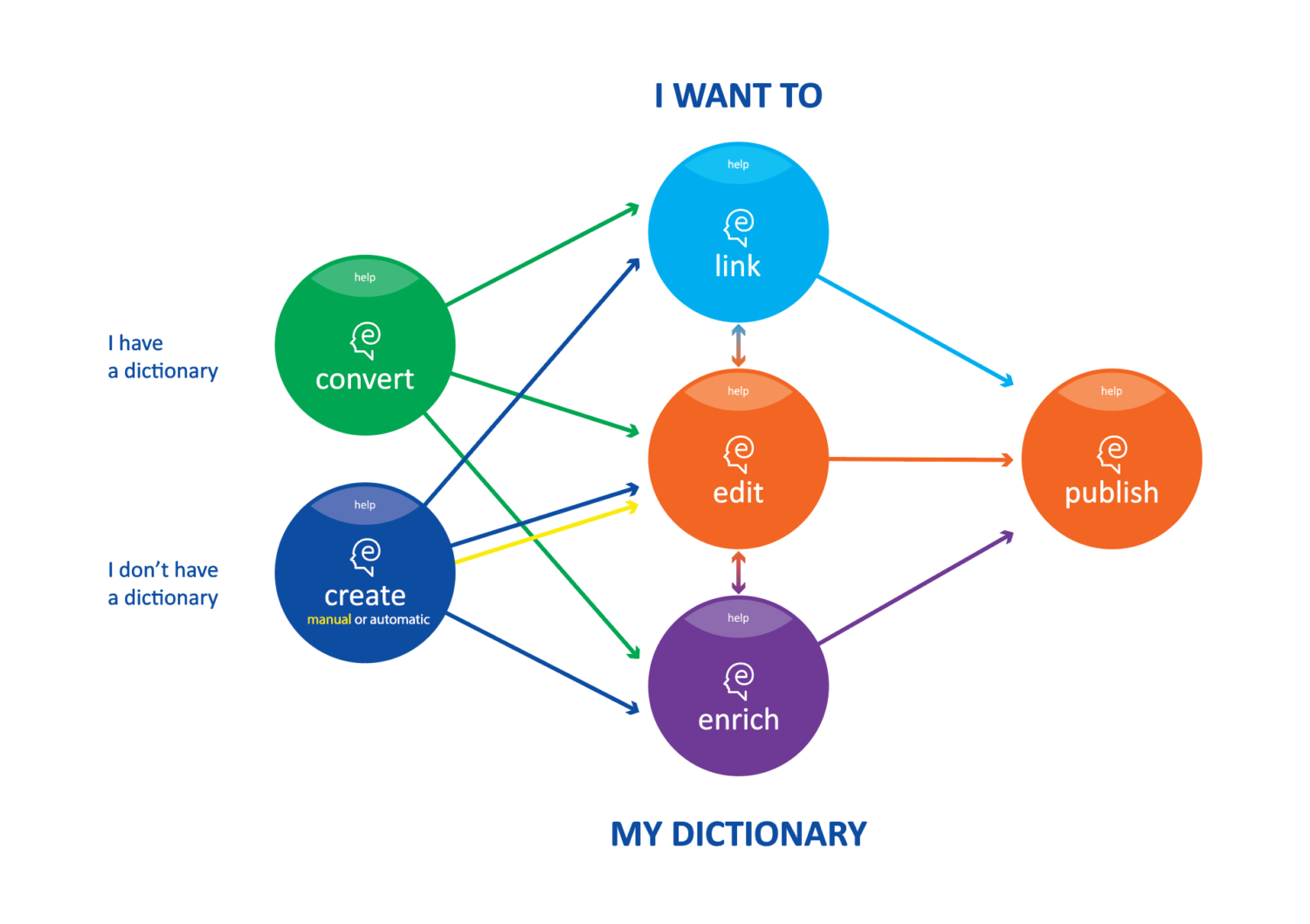
The ELEXIS project is aimed at developing a harmonised lexicographic infrastructure across Europe by providing the fundamental tools and services to create, edit, enrich, link or publish electronic dictionaries. Dobrovoljc has mostly been involved in the creation of the ELEXIS parallel sense-annotated corpus, which will be used for the development of word sense disambiguation tools and similar language technologies. To ensure long-term maintenance of the numerous project results, there is an ongoing process to establish a new ELEXIS CLARIN Knowledge Center.
The SLED project resulted in an equally important contribution to the local linguistic landscape, by developing the first monitor corpus for Slovenian. This represents an indispensable resource for monitoring language change in real time, such as identifying newly emerging words. The corpus contains monthly updated news articles from more than 100 media sites and is freely accessible for browsing through the user-friendly CLARIN.SI Kontext and noSketchEngine concordancers.
Future Plans
Dobrovoljc is part of the nationally funded project Development of Slovene in a Digital Environment, where she is involved in establishing the fundamental infrastructure for morphosyntactic processing of Slovene. This includes the development of a reference treebank and syntactic parser, as well as various online services promoting their use in language-oriented research.
Dobrovoljc says: 'Parsers are the perfect example of very small, yet smart pieces of AI that wouldn’t have been possible without the language resources in the background.' In her experience, CLARIN’s open data solutions make working with treebanks straightforward and accessible to the wider community. ‘I have no doubt I will remain a keen user of the CLARIN infrastructure for many years to come,’ says Dobrovoljc.
Dr Kaja Dobrovoljc, Research Associate at the University of Ljubljana and Jozef Stefan Institute.