The Project
In their recent project, researchers Bojan Evkoski and Senja Pollak first developed and then explained machine learning models in order to understand the language used by Slovenian members of parliament associated with different political leanings.
Based on transcriptions of Slovenian parliamentary debates from 2014 to 2020, their study focuses on the heated debates regarding the European migrant crisis. The researchers developed both classical machine learning and transformer language models to predict the left or right leaning of Members of Parliament (MPs) based on their speeches on the topic of migrants and the migration crisis. With both types of models showing great predictive success, the researchers then used explainability techniques in order to identify the key words and phrases that have the strongest influence on predicting the political leaning on the topic. Evkoski and Pollak argue that understanding the reasoning behind predictions is not just potentially beneficial for AI engineers in order to improve their models, but can also be helpful as a tool for qualitative analysis in interdisciplinary research.
The work ties in with a larger, national project on hate speech, and also complements two other recent projects that used the open-access ParlaMint dataset (see here and here).

Methodology
The researchers’ aim was to bring more insight into the speeches of parliamentarians (MPs) of different political leanings. The first step was to train machine learning models to predict whether an MP is left or right-leaning based on their speech. They then used explainability techniques on their models and extracted data in order to understand what it is that differentiates left and right-leaning speeches in parliament.
The researchers used the ParlaMint dataset as the basis for their study. In order to prepare the data for training a political leaning model based on the transcriptions, Evkovski and Pollak applied some pre-processing steps based on the metadata, such as removing guest and chair speeches. Next, they broadly labelled MPs ‘left’ or ‘right’ according to their political position based on the party name data. In a final step, speech selection according to the topic migration was applied, using a list of relevant keywords.
The team used two approaches to training machine learning models for text classification. The first was a classic bag of words feature extraction combined with a Linear SVM classifier. The second approach was the use of a state-of-the-art Transformer language model called SloBERTa. After cross-validating both approaches, the researchers selected the best model for each approach and trained it on the full data set in order to apply explainability analysis.
In order to explain the deep learning models, the team used the SHAP technique, which produces results that show which tokens, or words, contribute most towards predicting that a speech is ‘leftist’ or ‘rightist’.
The Value of XAI
The project is based on the belief that understanding and explaining what were previously considered ‘black box’ models is as important as developing and training them in the first place. Explainable AI (XAI) enables engineers to detect biases in the model, improve the model and test the security of the system, and is becoming a must both in industry and research. Computer scientists and social scientists alike are keen to find out how they can interpret and use the knowledge gained from model explanations.
For Evkoski and Pollak, explaining the decision-making of machine learning models (XAI) can be a great tool in interdisciplinary research: AI interpretability is an opportunity to bridge the gap between heavy, quantitative black-box research and the type of qualitative research that is more common among humanities and social science scholars. Here, the social sciences can make an important contribution: when the goal is not just to classify, but to understand patterns that appear across classification groups, XAI can complement qualitative research. In this project, the researchers used XAI to bridge the gap between computational and political linguistics.
This project, which focuses on a specific social theme, illustrates how XAI research can be the first step towards a more thorough qualitative approach. Pollak says: ‘In the field of computer science and natural language processing, people usually focus on solving problems and compete on who will get the highest score in terms of predictability on the data set. For those of us who are more interdisciplinary, we are really interested in the data behind the result, behind the predictions.’ She adds: ‘Computer scientists can work by themselves if it’s only about the technology. But as soon as it is applied somewhere, then I think it is necessary to have experts from the field where it is applied – not just in language technologies, but in general.’

The Results
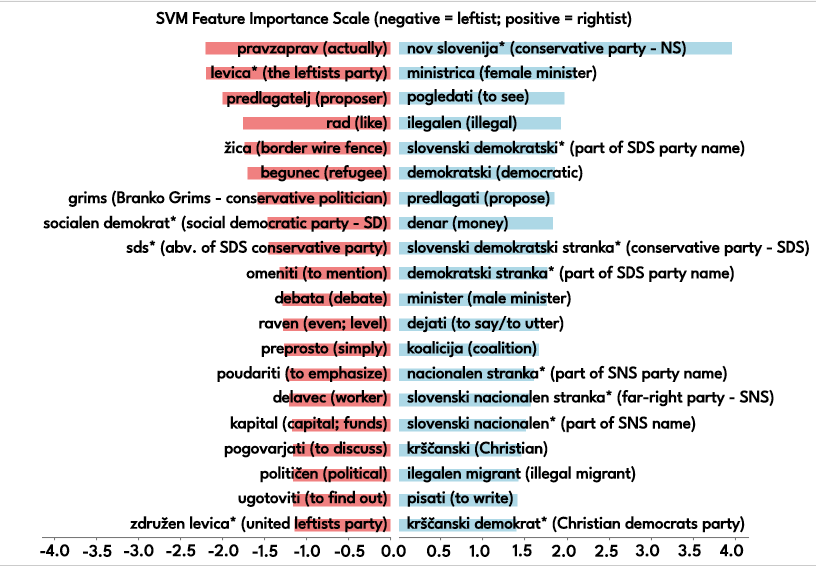
Overall (and as expected), the models showed that predicting parliamentary political leaning from speech transcriptions is possible, achieving high levels of accuracy. Once it was clear that statistical models can differentiate ‘leftist’ and ‘rightist’ speeches, the researchers investigated whether the explanation through feature importance also made sense from a political linguist’s perspective.
Indeed, the explanation of the models’ decisions confirmed the initial findings. Both model interpretations show that right-wing MPs tend to refer to the country name and its variations more, as well as emphasising the party names. In terms of migration, the focus is often on the illegal aspect of it, with terms such as ‘illegal migrant’ being used more frequently. Those MPs classed as leftist tend to refer to ‘refugee’ instead of ‘migrant’, and use consensus-building concepts such as ‘united’ or ‘debate’.

Pollak says they were very happy with these results, as they are meaningful and in line with broader social science findings. She notes: ‘If you look at the top distinguishing features, you get ‘refugee’ and ‘illegal’ and ‘illegal migrant’. If the model picks up such a difference, it shows that we are able to capture this discourse, these differences, with the models. We were surprised [how much the identified features] confirmed our intuition, way beyond the level of expectations. It rarely happens that you get these kinds of positive results immediately.’
On ParlaMint

The researchers based their work on the ParlaMint dataset, of which version 4.0 has just been released. Pollak: ‘Data sharing is crucial for the development of science. There is so much work behind developing the data sets – I really appreciate the work of all the people who are making these datasets public. It’s the basis for doing interesting research, to produce repeatable results, which is very important in science. There are usually a lot of grey zones – what data you can use, or where to find it, lots of negotiations – so if the dataset is ready, I'm always very grateful.’
Best Student Paper Award
Bojan Evkoski, Research Assistant, Institute of Contemporary History, Ljubljana
Senja Pollak, Research Associate, Jozef Stefan Institute, Ljubljana, Slovenia