The Project
Donate Speech is an ambitious collection of digital speech data intended for both academic and commercial use. Underpinned by an award-winning media campaign, Donate Speech (Lahjoita puhetta) has collected around 4000 hours of colloquial Finnish speech from more than 25 000 speakers during 2020 and early 2021. The project, a collaboration between the Finnish Broadcasting Company YLE, the Finnish State Development Company Ilmastorahasto Oy (formerly Vake Oy) and the University of Helsinki, set out to collect the speech data in order to accelerate the development and implementation of language-based Artificial Intelligence (AI) applications for Finnish.
Methodology
Donate Speech set out to collect everyday, spontaneous speech from as many different groups of Finnish speakers and as many individuals as possible, including speech from second-language Finnish learners.
Participants were able to donate speech via a web browser or Android or iOS mobile app, both of which offered a selection of tasks to encourage users to talk freely. Representatives from both industry and academia developed the general specifications for the app, which was then designed by software solutions development company Solita. The speech processing components are openly accessible and open source.

YLE developed around forty tasks with light-hearted themes for stimulating the collection of data, using videos, pictures and textual content, with an easy-to-use single button to start and stop the recording. Some of the most popular themes included Rakkain eläimeni (My dearest pet), Mistä kodikkuus syntyy? (What makes a cozy home?), Tärkeä esineeni (An important object of mine), Lempivaate (My favourite piece of clothing), Mikä suututtaa? (What’s infuriating?), Katson ikkunasta (While I am looking out of the window) and Kerro aamiaisesta? (What was your breakfast like?).
The total amount of time donated was added as a gamification element. The technical platform also asked participants to add some metadata, such as dialectical background, basic demographics such as age group, gender, mother tongue, profession, and level of education.
To raise awareness and encourage widespread participation, YLE launched an extensive public outreach campaign through its TV and radio channels. As part of the campaign, YLE made comical infomercials calling on the general public to donate speech, which were broadcast in the summer and autumn of 2020, with some reruns during the spring of 2021.

A key aspect of the Donate Speech project were the legal requirements surrounding the protection of personal data under European and national data protection legislation, most notably the General Data Protection Regulation (GDPR).
After careful consideration, it was determined that the project possessed ‘legitimate interest’ for processing personal data. A data protection impact assessment was also carried out, which found that the processing of personal data in the context of Donate Speech did not result in a high risk, based on the measures that had been put in place.
In practice, participants were provided with two documents: a brief statement including the basic terms of participation, which participants were asked to accept, as well as a more comprehensive data protection policy, outlining the way in which personal data are processed in the campaign and how donated speech samples could retrospectively be removed, if required.
The data will be deposited data with CLARIN, which offers a legal metadata classification system for all datasets, including those that cannot be made openly available. Users are informed of potential restrictions they need to be aware of when accessing the data. The material can be shared with individual researchers, universities and research organisations or private companies that need it in order to study language or artificial intelligence, for developing AI solutions or for higher education purposes.
Outcome
In total, more than 25 000 citizens in Finland donated more than 220 000 speech samples comprising roughly 4000 hours of colloquial speech to be used by academia and industry for developing and researching language and AI applications.
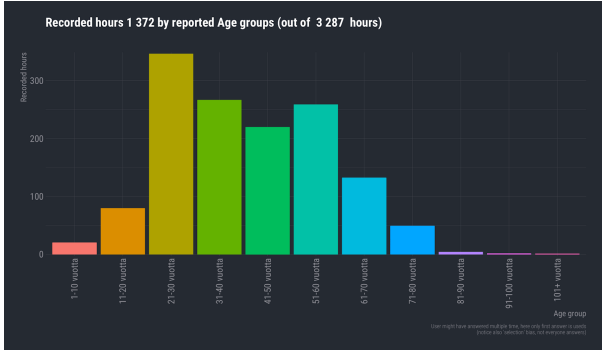
Based on the available metadata, people between twenty and sixty years of age made around three quarters of the donations, with young women being most active. Donations were made from all the regions of Finland, with ninety-five per cent of the participants being native speakers.
More than two thirds of the data was donated by students, pensioners, teachers, entrepreneurs, experts and nurses, with the remainder contributed by more than thirty other professions from diverse parts of society. Almost two thirds had a higher education and almost a third a secondary education.
The web interface was more popular than the apps, and was used by two thirds of the participants. Most of the recordings were between ten seconds and three minutes long, with an average length of thirty to sixty seconds.
Initial random sampling and manual transcription produced encouraging results and suggests that the material is on average no more difficult to recognise than previously recorded speech data under more controlled conditions.
In terms of the campaign’s success, the media campaign turned out to be key. Indeed, the media campaign has received two prestigious awards. In the spring of 2021, it won first prize in the mobile service category of the annual marketing competition GrandOne. Later that year, it won the category of Best European Digital Audio Project 2021 in the annual Prix Europa competition for European broadcasters. The prize was awarded for a fresh way to conceptualise broadcasting and its output, the new cooperation model between commercial and public service entities and a broadcasting company such as YLE, as well as a great web service accompanied by a light-hearted and humorous campaign.
It is anticipated that the digital speech data will be useful for the development of a range of lT and speech processing capacities. The data will allow much more precise training of speaker-independent supervised speech recognition, as well as new directions in research in unsupervised or minimally supervised machine learning of speech processing using current neural network technology. These advancements could improve performances of speech bots or automated call centres, as well as speech-enabled form filling, potentially providing access to digital services for people who have typically been excluded, such as those with impaired vision or low finger dexterity.
Several large companies involved in speech recognition, such as Microsoft and IBM, have already shown interest in evaluating the data, as it may enable them to train their systems to become better at recognising Finnish.

Publications and Future Plans
Donate Speech has already extended the project to include Finnish-Swedish or the Swedish spoken in Finland (Donera Prat), and is thinking of including more languages in the future. Krister Lindén says: ‘The software is there, and the legal framework is there. It only took YLE a couple of person months to start a similar campaign for Finnish-Swedish, because the framework was already there. Now we’re thinking of going ahead and doing this for Sami as well, and then it will require even less time and effort.’
A book chapter on the project is due to appear in the forthcoming edited volume CLARIN. The Infrastructure for Language Resources (Berlin: de Gruyter, 2022), edited by Darja Fišer and Andreas Witt.