Written by Martin Puttkammer
Over the past two decades, research and development projects in South African language technologies (mostly funded by the South African government through their National Centre for Human Language Technologies initiative) have generated several natural language processing ( ) resources in the form of data, core technologies, applications, and systems, which are immensely valuable for the future development of the official South African languages. Although these tools and resources can be obtained in a timely fashion from the Resource Management Agency of the South African Centre for Digital Language Resources (SADiLaR), their accessibility can still be considered limited, in the sense that technically proficient people or organizations are required to utilize these technologies. This makes it difficult for other potential users, such as Digital Humanities and Social Science researchers, to benefit from them in their work.
To increase the visibility, access, and impact of these technologies, 61 of the existing text-based core technologies, developed by the Centre for Text Technologies (CTexT) over a ten-year period, were ported to Java-based technologies. These were in turn made available to developers via the RESTful and to end-users through an intuitive web interface (NCHLT Web Services) as well as in a stand-alone interface (CTexTools). The technologies include optical character recognition (OCR) engines, tokenizers, sentence boundary detectors, part-of-speech (PoS) taggers, named-entity recognizers, and phrase chunkers as well as a language identifier for ten of the official South African languages.
NCHLT Web Services
Apart from the RESTful API aimed at developers, SADiLaR has also developed an automated system to assist end-users. This was done through the development of a web-based, user-friendly graphical user interface (see Figure 46) which provides predefined chains of the web services available via the API. For example, if a user needs to perform part-of-speech (PoS) tagging on a document, he or she can upload the document and select PoS tagging and the relevant language. The system will automatically perform tokenization and sentence boundary detection before using the PoS tagging service to tag the user’s document.
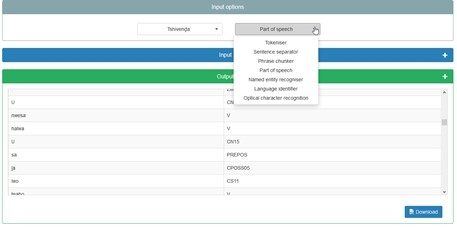
CTexTools
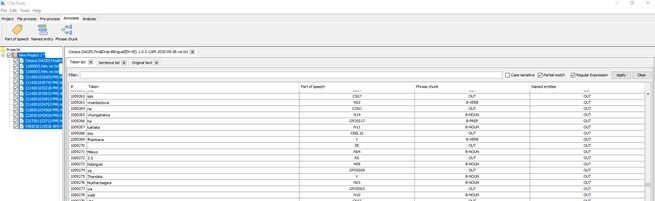
The web services and API can be accessed at a dedicated website hosted by SADiLaR, while CTexTools can be downloaded from the SADiLaR repository. More detailed descriptions of the technologies and web services are available in Eiselen and Puttkammer (2014) and Puttkammer et al. (2018).
References
Eiselen, R., and Puttkammer, M. 2014. Developing Text Resources for Ten South African Languages. In Proceedings of LREC2014, 3698–3703.
Puttkammer, M., Eiselen, R., Hocking, J., and Koen, F. 2018. NLP Web Services for Resource-Scarce Languages. In Proceedings of LREC2018, 43–49.