Written by Eiríkur Rögnvaldsson
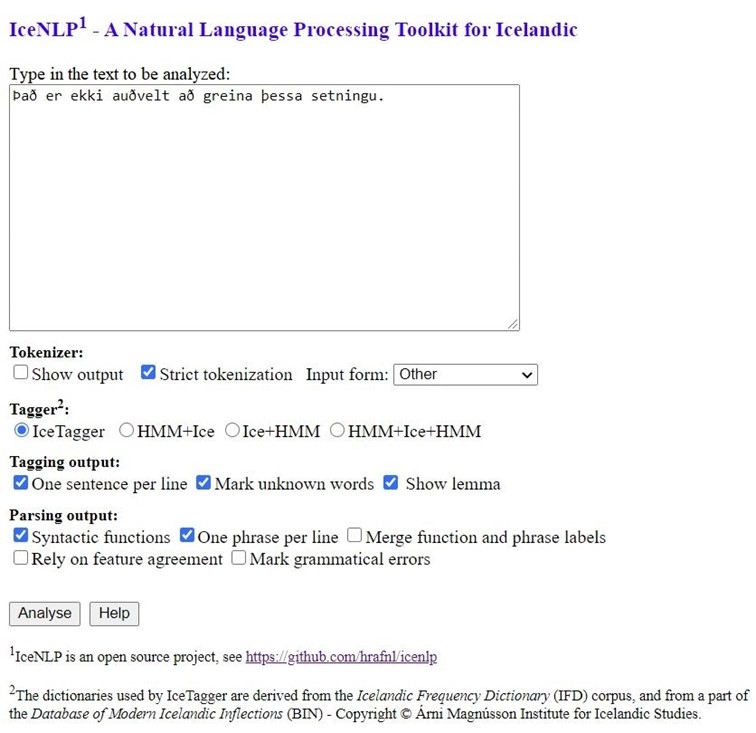
IceNLP is an open source toolkit for processing and analysing Icelandic text. It can be downloaded from the CLARIN-IS repository under the GNU General Public Licence, version 2. An online version is also available on the Reykjavík University website. IceNLP was originally developed by Hrafn Loftsson, Associate Professor in Computer Science at Reykjavik University, as a part of his PhD studies during the years 2004–2007. Since then, students at Reykjavik University and the University of Iceland have helped in developing individual components. IceNLP is written as a collection of Java classes. Its main modules are the following:
- A tokenizer. This module performs both word tokenization and sentence segmentation.
- A morphological analyser (IceMorphy; Loftsson 2008). The program provides the tag profile (the ambiguity class) for known words by looking up words in its dictionary. The tag profile for unknown words is guessed by applying rules based on suffixes and endings.
- A linguistic rule-based PoS tagger (IceTagger; Loftsson 2008). The tagger produces disambiguated morphosyntactic tags. It uses IceMorphy for morphological analysis and applies both local rules and heuristics for disambiguation.
- A statistical PoS tagger (TriTagger). This trigram tagger is a re-implementation of Brandt’s well-known HMM tagger (TnT).
- A lemmatizer (Lemmald; Ingason et al. 2008). The method used combines a data-driven method with linguistic knowledge to maximize accuracy.
- A shallow parser (IceParser; Loftsson and Rögnvaldsson 2007). The parser marks both constituent structure and syntactic functions using a cascade of finite-state transducers.
Most of these modules were the first of their kind to be developed for Icelandic. Individual components of IceNLP can be run independently, or the Java clusters in question connected directly to software that is being developed.
Hrafn Loftsson and his students and collaborators have used IceNLP in a number of projects and publications; for instance, in developing intelligent computer-assisted language learning applications (ICALL; Volodina et al., 2012). They have also used the toolkit for experimenting with the Apertium machine translation system where they replaced some of the Apertium original modules with modules from IceNLP (Brandt et al. 2011).
Other researchers and developers have also made extensive use of IceNLP. It was used for preprocessing texts in the manually ann
otated one-million-word Icelandic Parsed Historical Corpus (IcePaHC; Rögnvaldsson et al., 2012), which is accessible via CLARIN-IS and has proven crucial both for studying Icelandic diachronic syntax and both developing and training parsers for Icelandic. IceNLP was also used for tokenizing, lemmatizing and tagging the Tagged Icelandic Corpus (Mörkuð íslensk málheild, MÍM; Helgadóttir et al. 2012), a 25 million-word balanced tagged corpus of Modern Icelandic that’s also accessible via CLARIN-IS. Furthermore, IceNLP was an essential tool in the development of the first Icelandic Frequency Dictionary of children’s speech (Einarsdóttir et al. 2019).
IceNLP is the only toolkit that comprises several different tools for analysing Icelandic text, and also the only one that is available online (Figure 1). Thus, it is a very important tool for researchers working on Icelandic, especially those who are not very technically oriented.