Blog post written by Janne Bondi Johannessen, Kristin Hagen, Anders Nøklestad, and Joel Priestley, edited by Darja Fišer and Jakob Lenardič
The Glossa search system is an advanced, user-friendly interface for searching in written text and transcripts of audio or video. Glossa is developed at the Text Laboratory at the University of Oslo, and reimplemented in 2014 – 2018 in the CLARINO project. Glossa is used in a series of speech, text and parallel corpora available at CLARINO Text Laboratory Centre. The Glossa tool itself is also downloadable from the CLARINO Text Laboratory Centre site and from GitHub.
Glossa allows researchers to search for a word, a part of a word, individual sounds, or several words and to search for grammatical information, as well as to filter the results on the basis of various sociolinguistic metadata, such as the gender and the age of the informant. The search results are presented as concordances, as shown in the figures below, but can also be rendered as pdfs, plotted on maps (via geographical coordinates and Google Maps), or shown as frequency lists. The data can be automatically translated, for most corpora via the Google Translate API, and also downloaded in spreadsheet format. For speech corpora, the integrated media player provides access to the corresponding media sequence of each query result.
Glossa supports login with eduGAIN, CLARIN and Feide (the latter for Norwegian users). The Glossa installation is based on widely available technologies such as Java, MySQL and IMS Corpus Workbench. Search and result processing functions are accessed using familiar browser buttons and menus, requiring no special technological background. For those familiar with the IMS Corpus Workbench, advanced CQP queries can be performed directly using a specific search box. Glossa also supports CLARIN Federated Content Search (FCS).
The figures below show Glossa being used with the speech corpus CANS - Corpus of American Nordic Speech and the NORM Corpus, a learner corpus of more than 5000 pupil essays.

Figure 1: The main search page of CANS. To the left are all the searchable metadata categories with the number of selected speakers and tokens at the top. The Show speakers button will show the speakers that are currently selected. Below the corpus logo, there is a search box with three different search alternatives: Simple, which allows a search for a simple word or phrase, Extended (se Figure 2), and CQP query.

Figure 2: The extended search interface. In addition to the various search term modifiers available via the checkboxes, clicking the menu icon reveals a list of additional attributes, such as part of speech. The plus icon is used to extend the search term with additional text boxes, whereas the Or button yields further text boxes for or-searches (disjunction). Note that you can tick the Phonetic form box if you want to search directly in the phonetic transcriptions of CANS (CANS has two aligned transcriptions of each sequence, one orthographic and one phonetic).

Figure 3: A search for før (“before”) in segment initial position returns 25 matches. Both the orthographic and the phonetic transcription of the sequence are shown, together with an option to see the metadata pertaining to the speaker (click the speaker ID), to translate, to play video or audio, or to see a spectrogram of the sequence.
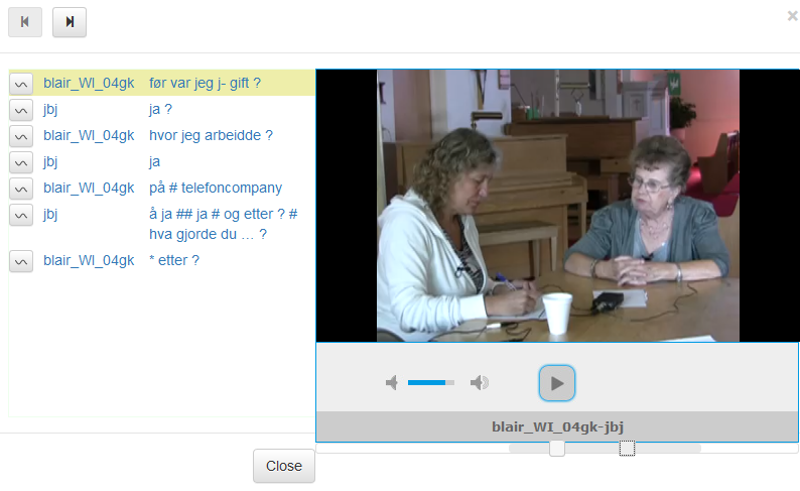
Figure 4: Video playback of the search result. More context can be accessed by moving the square buttons on the slider bar.
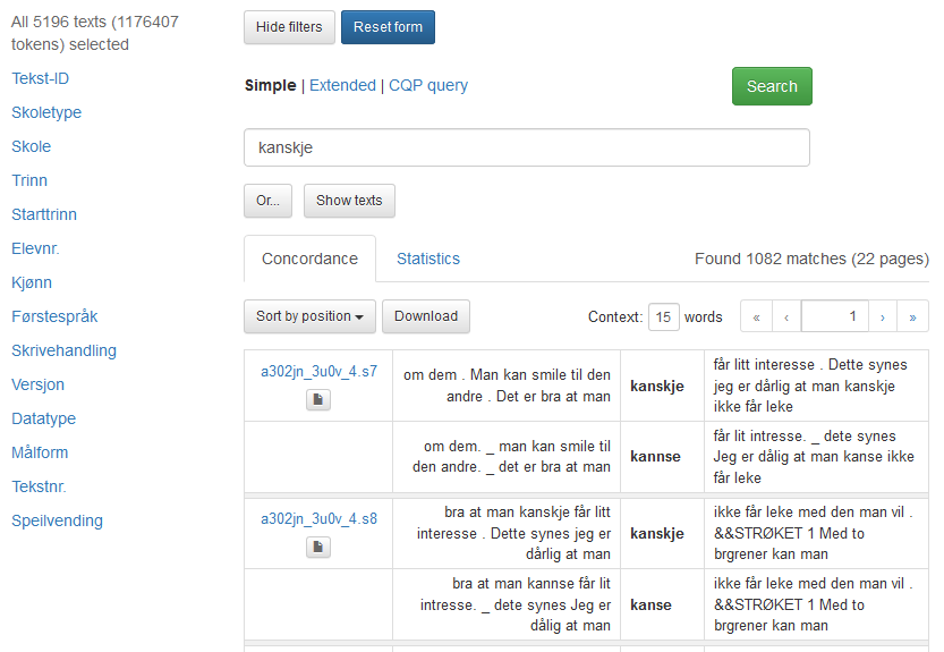
Figure 5: A search result for kanskje (“maybe”) in the pupils' text corpus NORM. The search interface is the same as in the speech corpus CANS, but the metadata menu on the left is different. If you click on the document symbol to the left of the search result, you will see a pdf of the pupil’s text as shown in Figure 6. Note that this corpus has two aligned versions of the text, the original text and corrected text. You can search in both versions, although the orthographic search is the default.

Figure 6: An essay in the NORM corpus.
Glossa is an essential search system for researchers working with language variation and change, since it allows them to compare language use across different age groups, different periods (there are nearly a hundred years between the oldest and newest recordings in some of the speech corpora available through Glossa) and different places. The dialect corpora and the heritage language corpora, such as Corpus of American Nordic Speech v.3 and Nordic Dialect Corpus v. 4.0, are often used in this kind of research and queried with Glossa. The written language corpora, such as The NORINT Corpus, which presents the use of Norwegian as a second language, and The Lexicographic Corpus for Norwegian Bokmål, have been successfully used for practical work on dictionaries and language planning and standardization, where it is vital that different kinds of texts can be distinguished easily on the basis of the sociolinguistic metadata filter options.
References
Nøklestad, Anders, Hagen, Kristin, Johannessen, Janne Bondi, Kosek, Michal and Joel Priestley. 2017. A modernised version of the Glossa corpus search system. In Jörg Tiedemann (ed.): Proceedings of the 21st Nordic Conference on Computational Linguistics (NoDaLiDa). 2017, 251-254.
Kosek, Michal, Anders Nøklestad, Joel Priestley, Kristin Hagen, and Janne Bondi Johannessen. 2015. In Gintarė Grigonytė, Simon Clematide, Andrius Utka and Martin Volk (eds.): Visualisation in speech corpora: maps and waves in the Glossa system, Proceedings of the Workshop on Innovative Corpus Query and Visualization Tools at NODALIDA 2015, May 11-13, 2015, Vilnius, Lithuania, NEALT Proceedings Series 25, 23–31.
Click here to read more about Tour de CLARIN