Blog post written by Michal Křen
The Czech CLARIN Knowledge Centre for Corpus Linguistics has been recognized by CLARIN on December 4, 2018.
The centre is based at the Institute of the Czech National Corpus, Faculty of Arts, Charles University, Prague. Czech Natiional Corpus (CNC) is a long-term academic project with the main aim to continuously map the Czech language by building, annotating and providing access to a variety of large general-purpose corpora. CNC also develops specialized web-based applications for user-friendly access to the corpora and offers wide-ranging user support which includes a user forum with Q&A, bug reporting, detailed documentation and a knowledge base.
CNC is recognized by the Ministry of Education, Youth and Sports of the Czech Republic as a research infrastructure and included on the Roadmap of Large Research Infrastructures of the Czech Republic for 2016-2022. CNC is an associated member of the CLARIN-CZ consortium with established long-term collaboration with LINDAT/CLARIN. CNC is also a CLARIN endpoint and it supports (Shibboleth) as one of the options for accessing the CNC resources.
In addition to this service-oriented line of work, CNC is also a research centre that promotes an empirical approach to language and runs a PhD programme in Corpus Linguistics.
The CNC activities can be divided into the three main areas:
-
Data collection. Focusing on quantity, quality, and variety, the CNC corpora feature careful text selection, reliable annotation and rich metadata. The following is currently covered:
- contemporary written Czech: SYN-series corpora (total size 4.2 billion running words) which also include representative 100-million corpora released every five years;
- contemporary spoken Czech: corpora consisting solely of spontaneous informal conversation of the ORAL and ORTOFON series (total size 5.3 million running words);
- InterCorp multilingual parallel corpus: manually aligned and proofread fiction texts supplemented by collections of automatically processed texts from various domains (total size 1.5 billion running words in all 40+ languages);
- specialised corpora include historical Czech (DIAKORP), Czech dialects (DIALEKT), and many more.
- Annotation involves data curation, metadata annotation, morphological tagging and syntactic parsing. For all these procedures, CNC uses open-source software, third-party tools, as well as in-house developed specialised tools. The third-party tools include Czech morphological lexicon MorfFlex CZ, MorphoDiTa tagger, and Onion deduplication tool, to name just a few. The in-house developed tools include mainly Phras module for identification of idioms, Mluvka for management of distributed spoken data collection, and parallel text alignment editor InterText.
-
User application development. We recognize the key importance of presenting corpora in an intuitive way that makes them accessible to researchers from various fields of social sciences and humanities. The following web applications are currently offered:
- KonText – a general-purpose corpus query interface and concordancer with an advanced subcorpus manager, parallel corpus support and support for word-to-sound alignment;
- SyD – corpus-based analysis of language variants, both synchronic and diachronic;
- Morfio – identification of derivational models in Czech including estimation of their morphological productivity;
- KWords – corpus-based keyword analysis;
- Treq – translation equivalent search interface based on the InterCorp parallel corpus.
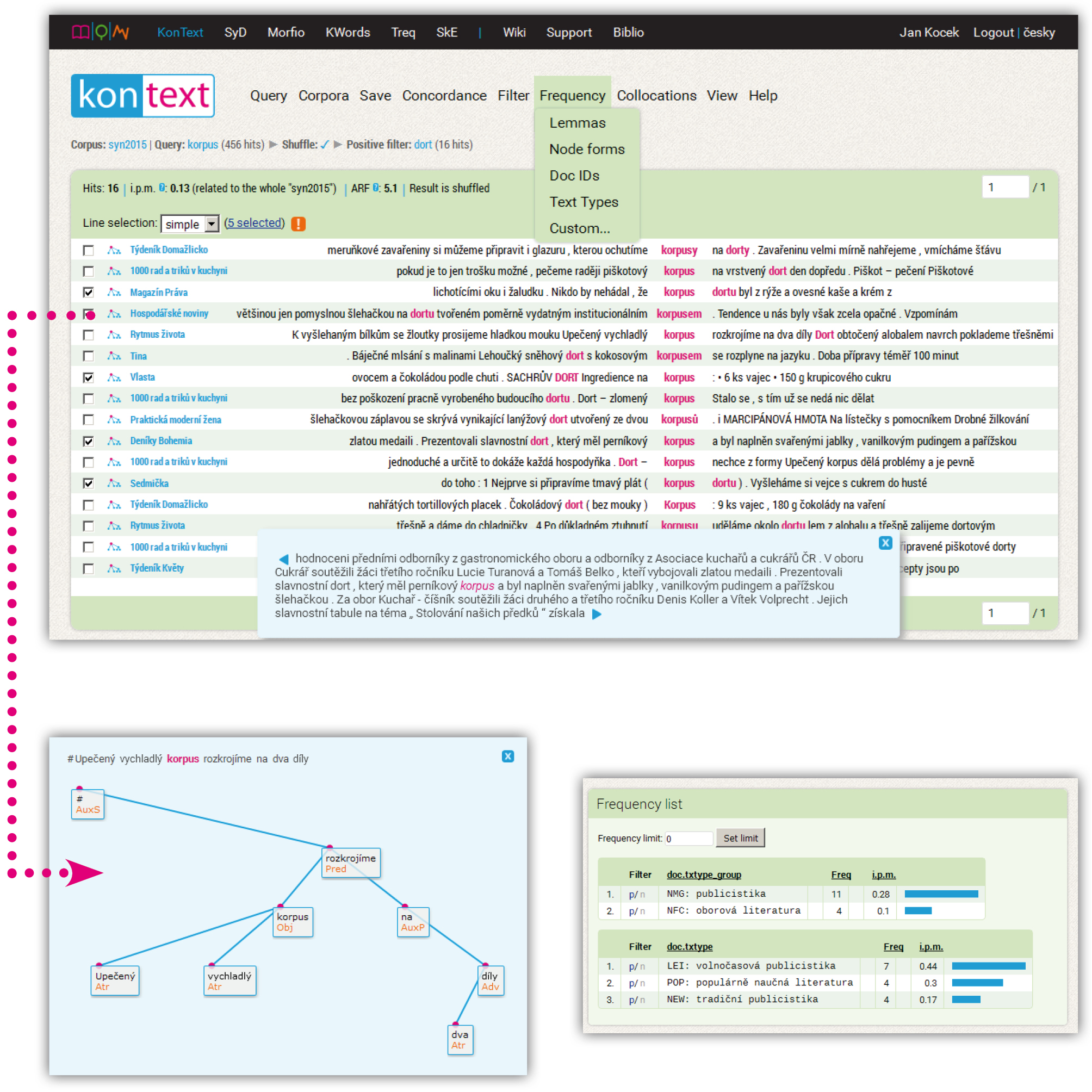
KonText user application being actively developed by the CNC
Currently, CNC has 7,500+ registered active users who perform (on average) 3,000+ corpus queries per day. The repository of CNC-based research outputs has yielded more than 150 theses (bachelor, master or doctoral) defended a year.
The CNC user support and related services are available also through the CLARIN K-centre. This includes:
- K-centre Helpdesk and CNC User Forum, virtual platforms for active user support and feedback. The CNC user forum features also a discussion forum (with Q&A) that can handle requests for new application features as well as bug reports.
- Documentation and knowledge base for CNC applications, data and services. It provides interdisciplinary guidance and promotes empirical methods in language research. It also features an on-line tutorial aimed at both beginners and advanced users.
- Repository of CNC-based resources and research output that can also serve as a bibliography for looking up information concerning the corpus research on Czech.
- Repository of corpus-based exercises (Czech only) for L1 and L2 language teaching.
- Consulting, education, and training: in addition to the general user workshop held on a regular basis twice a year, workshops on various topics are held upon request.
- Corpus hosting: the service includes final technical processing of user-compiled corpora, quality checks, and public access with related services.
- Customised data packages: data sets prepared on demand and extracted from the CNC corpora while observing the legal limitations that may not allow for redistribution of the texts per se.
Our expertise includes not only data formats, text curation, annotation, metadata encoding and corpus querying, but also empirical research on the Czech language, corpus linguistics methodology and statistical methods. The centre can also provide external pointers to other institutions regarding any aspect of Czech language including language resources and natural language processing.

CNC User Workshop
Click here to read more about Tour de CLARIN