Blog post written by Brian MacWhinney, edited by Jakob Lenardič and Darja Fišer
TalkBank, which was recognized as a CLARIN Knowledge Centre in 2016, is the world’s largest open access integrated repository for spoken language data. It provides language corpora and other audio resources to support researchers in Psychology, Linguistics, Education, Computer Science, and Speech Pathology. The National Institutes of Health and the National Science Foundation have provided support for the construction of five components of TalkBank:
- AphasiaBank for the study of language in aphasia in six languages,
- CHILDES for the study of child language development in 42 languages from infancy to age 6,
- FluencyBank for the study of language fluency and disfluency in stuttering, aphasia, second language learning, and normal processing,
- HomeBank for the study through automatic speech recognition of untranscribed daylong recordings in the home and elsewhere, and
- PhonBank for the analysis of children’s phonological development in 18 languages.
The five components, which involve multiple corpora collected and encoded according to the same principles contributed by individual researchers from all over the world, form very large collections that are being used extensively to study the cognitive, neurological, developmental, and social bases of language processing and structure. In addition to our support for these five areas, TalkBank also promotes the growth of corpora in nine other related areas:
- ASDBank for the study of language in autism spectrum disorder,
- BilingBank for the study of bilingualism and multilingualism,
- CABank for the study of conversation using the methods of Conversation Analysis,
- ClassBank for the study of language in the classroom,
- DementiaBank for the study of language in dementia,
- RHDBank for the study of language in right hemisphere damage,
- SamtaleBank for the study of conversations in Danish,
- SLABank for the study of second language learning, and
- TBIBank for the study of language in traumatic brain injury.
TalkBank Principles
The TalkBank system is grounded on six basic principles: maximally open data-sharing, use of the CHAT transcription format, CHAT-consistent software, interoperability, responsivity to research group needs, and adoption of international standards.
Maximally open data-sharing
In the physical sciences, the process of data-sharing is taken as a given. However, data-sharing has not yet been adopted as the norm in the social sciences and humanities. This failure to share research results – much of it supported by public funds – represents a big loss to science. Researchers often cite privacy concerns as reasons for not sharing data on spoken interaction. In response to this, TalkBank provides a variety of options in which data can be made available to other researchers, while still preserving participant anonymity, such as password protection and pseudonymization of the participants’ first and last names.
CHAT Transcription format
As individual researchers sample from the great diversity of language contexts, they tend to develop idiosyncratic, incompatible methods for language transcription and analysis. In order to provide maximum harmonization across these formats, TalkBank has created an inclusive transcription standard, called CHAT, that recognizes all the features required by different disciplinary analyses. Furthermore, CHAT allows researchers to link transcripts directly to the audio or video, which significantly speeds up transcription and improves accuracy.
CHAT-consistent software
The basic program for analysis of TalkBank data is called CLAN. For language analysis, CLAN automatically computes clinical measures, such as the mean length of the utterance (MLU), the Type-Token Ratio (TRR), Brown’s morphemes (for children), and several other values, without errors. Figure 1 illustrates the use of a dialog in CLAN’s EVAL program for comparing a transcript from a single participant with those from matched participants in the larger AphasiaBank database.
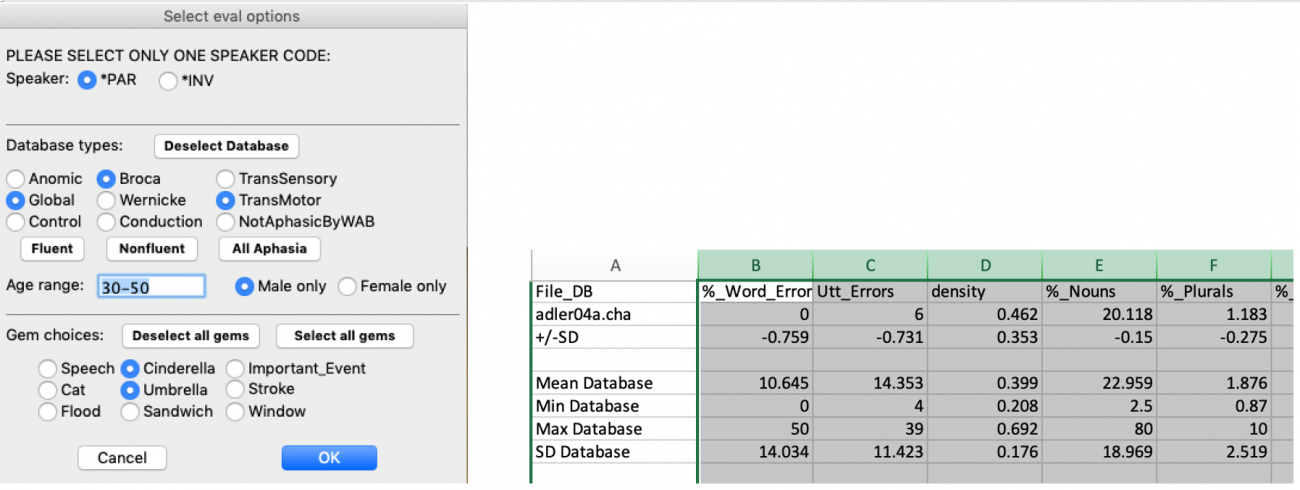
Much of the morphosyntactic analysis in CLAN depends on the use of automatic part-of-speech taggers and grammatical dependency taggers that we have constructed for Cantonese, Chinese, Danish, Dutch, English, French, German, Hebrew, Japanese, Italian, and Spanish. The TalkBankDB database search engine permits rapid searches of the database, CQL queries, graphic displays, and downloading of data in CSV format for further statistical analysis. A user-friendly guide for using CLAN that does not presuppose technical knowledge was written by Nan Bernstein Ratner (University of Maryland) and Shelley B. Brundage (George Washington University).
Interoperability
The PhonBank component of TalkBank has developed a separate program called Phon, which provides extensive support for the analysis of phonological data. Crucially, the entire code and functionality of the popular PRAAT software for phonetic transcription are now included inside Phon. Compatibility with other common formats, including Anvil, CONNL, DataVyu, ELAN, EXMARaLDA, LENA, Praat, SRT, SALT, and Transcriber is achieved through translation programs inside CLAN. Recently, Christophe Parisse from INSERM/CNRS and Ortolang, also the repository of the French CLARIN observer, has built a powerful new editor called TRJS, which is used for the transcription, editing and visualization of data and corpora of spoken language and which works directly with the CHAT, ELAN, and formats.
Responsivity to research community needs
TalkBank seeks to be maximally responsive to the needs of individual researchers and their research communities, as well as instructors and clinicians. Our most basic principle is that we attempt to implement all features that are suggested by users in terms of software features, data coverage, documentation, and user support.
Each corpus page includes a link to a facility called the TalkBank browser that allows users to play back linked multimedia corpora directly in their web browser (Figure 2). Users can choose to have continuous playback or playback of specific sections or utterances. For AphasiaBank, FluencyBank, RHDBank, and TBIBank, there are web pages with example videos and instructional commentary designed for use in teaching about language disabilities.
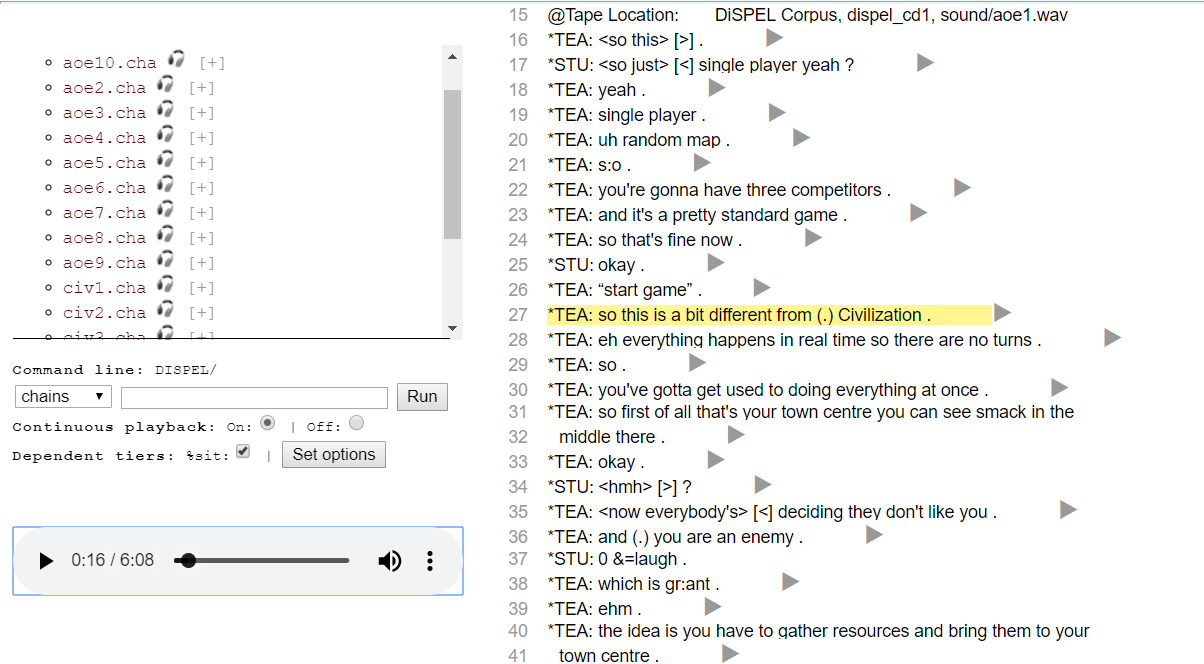
TalkBank provides several avenues for user support. In addition to detailed manuals, configuration as a CLARIN Knowledge Centre, and GoogleGroups lists for user support, we have created screencast tutorials that explain how to use the database and the tools. These are hosted both at our own servers and through YouTube. We also conduct presentations and workshops each year at international conferences, such as IASCL, ASHA, LSA, Academy of Aphasia, LREC, and CLARIN.
International Standards
The sixth basic TalkBank principle is our commitment to international standards for database and language technology. Toward this end, TalkBank has joined the CLARIN federation and is now one of the two members of CLARIN infrastructure outside Europe. In 2017, TalkBank received the approval of the Core Trust Seal, which emphasizes the adoption of international standards in data access, protection of confidentiality, organizational infrastructure, data integrity, data storage, data curation, and data preservation. To this end, TalkBank maintains incremental GIT repositories for all of its datasets, where researchers interested in replicating earlier analyses can obtain copies of segments of the database from any particular date. In addition, 74,520 language resources in the Virtual Language Observatory (about 10% of all resources listed) derive from TalkBank corpora. Moreover, these resources are all available through open access in a single, consistent, fully documented, and validated format.
Click here to read more about Tour de CLARIN