By Tanara Zingano Kuhn, Rina Zviel Girshin, Špela Arhar Holdt, Kristina Koppel, Iztok Kosem, Carole Tiberius, and Ana R. Luís
In February 2019, members of the enetCollect COST Action gathered in Brussels for the first edition of the Crowdfest, a hackathon for the development of projects for language learning using crowdsourcing techniques. At this event, the present project leader, together with a researcher who had already expressed interest in collaborating, pitched her idea to use crowdsourcing to remove offensive and/or sensitive content from corpora in order to find a more adequate process of making pedagogical corpora that could be used to develop a Portuguese version of the auxiliary language learning resource Sketch Engine for Language Learning − SKELL. Then, two other researchers joined them in the hackathon, and together they brainstormed ideas and came up with a first methodological approach. Later that year, other researchers from different countries joined the group and further developed the initial methodology, leading to the proposal of a crowdsourcing experiment using Pybossa. The languages for which the experiment was conducted were Dutch, Serbian, Slovene, and Portuguese.
The lessons learned from this experiment have led us to make some changes to the initial idea. Firstly, the final application of the corpora was broadened. Not only did we want to develop SKELL for each one of the languages, but we also wanted to make the corpora available for language teachers, lexicographers, and researchers. Secondly, the objective of the crowdsourcing tasks changed from corpus filtering to corpus labelling. This way, sentences are not removed from the corpus, but rather labelled, so users can choose the sentences they want to use depending on their objectives. Finally, we decided to adopt a more engaging approach: a gamified solution. This is when CrowLL – the Crowdsourcing for Language Learning game was born.
Objectives and Outcomes
The main goal of this project was to create manually annotated corpora for teaching and learning purposes of Brazilian Portuguese, Dutch, Estonian, and Slovene that can be used by lexicographers, language teachers, and NLP researchers, as well as for the development of SKELL for each of the languages. The process involved two stages, namely, data preparation and game development, each with its own outcomes.
In the future, researchers wanting to create such annotated corpora for their language can choose either the expert approach (the annotation guidelines), or/and opt for crowdsourcing (the game).
STAGE 1 – Data Preparation
In this stage, data for the game was prepared, which involved:
1. Definition of the source corpora from which sentences would be extracted
2. Provision of pedagogically oriented GDEX configurations
3. Creation of lemma lists to extract sentences from the corpora.
The process is described in detail in here.
The result is manually annotated corpora for teaching and learning Dutch, Estonian, Slovene, and Brazilian Portuguese, each containing 10.000 sentences. Sentences in the corpora are marked with Y if the sentence was considered to be ‘problematic’ for teaching the language and N if considered to be ‘non-problematic’. All the problematic sentences additionally have labels indicating the category of the problem (offensive, vulgar, sensitive content, grammar/spelling problems, incomprehensible/lack of context). These corpora are available on PORTULAN CLARIN, together with the guidelines and the list of lemmas used for extraction.
STAGE 2 – Game Development
By streamlining annotation and including more participants in the process, larger amounts of data can be manually processed. This is why we developed a crowdsourcing-based game for further corpus growth. The code for gamified annotation is published on Github as open access under an Apache 2.0 licence.
The idea for CrowLL was originally inspired by the Matchin game (Hacker and von Ahn, 2009). In this, two players compete with each other to guess which of the two pictures they are shown will be chosen by their opponent. If their predictions match, they score points. For CrowLL, we opted to start with the development of a single-player mode, where players get scores if their choices match those previously made by other players. This means that, to launch the game, previously annotated sentences must be fed to the game. We thus used the manually annotated corpora created in stage 1 as ‘seed corpora’ so that players’ answers can be matched to existing answers (experts’ annotations).
In terms of the type of crowdsourced work, we consider CrowLL as a crowdrating game, given that ‘crowdrating systems commonly seek to harness the so-called wisdom of crowds (Surowiecki, 2005) to perform collective assessments or predictions. In this case, the emergent value arises from a huge number of homogeneous “votes”’ (Morschheuser et al., 2017, p. 27). With this game, the definition of whether a sentence is problematic or not, to which category of problem it belongs, and what constituent part of the sentence is problematic, will emerge from the majority consensus.
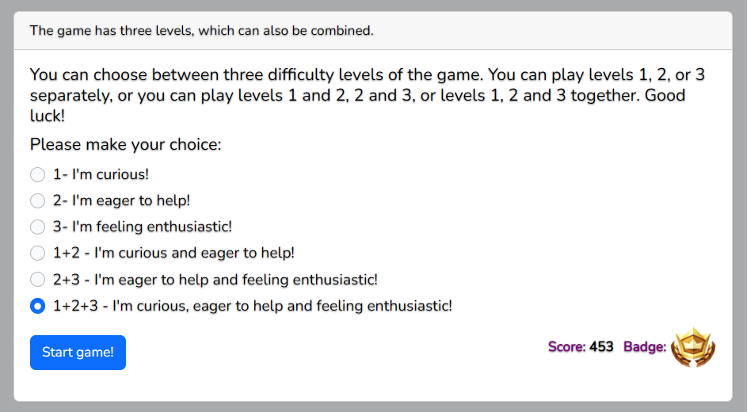
At present, the CrowLL game can be played on computers or mobiles devices at this link.
Future Steps
There are several next steps that we envision. Firstly, we intend to collect and analyse the players’ answers to draw some conclusions regarding how people judge offensive language/sensitive content. Some questions we would like to answer are: how much variability is there among people in terms of sentence judgement? Is there any factor that might contribute to this variability? What are the characteristics of the sentences considered by the crowd to be offensive/vulgar or to have sensitive content? Do these characteristics vary among languages?
We would also like to conduct a user evaluation survey with selected players to get feedback on the game. Our focus would be on several aspects, from usability elements to gamification.
Finally, after having collected a significant number of answers, we plan to start STAGE 3 of the project. In the third phase, machine learning models for all languages involved will be trained to automatically identify problematic content (manually categorised by the players) in (web) corpora. We expect this automatic identification of problematic content will facilitate the compilation of larger, clean corpora.
Alignment with CLARIN's Strategic Priorities
The CrowLL project is very much aligned with CLARIN's strategy of providing data for facilitating research in data science and artificial intelligence, as well as in social sciences and humanities. The project is also strongly committed to the FAIR principles, promoting open science and scalability of planned results. One of the strengths of the project is innovation, both in terms of data and methodology. Moreover, the corpus resources produced by the current project will extend the scope of the CLARIN Resource Families initiative, more specifically, the section on manually annotated corpora.
Creating annotated corpora of several languages will enable research on linguistic levels as well as training of tools, while accompanying documentation, gamification and presentations facilitate further expansion of this type of data collection to other languages. The resulting corpora will also support language teachers by providing labelled example sentences that can be used in class and lexicographers, who can use these corpora as a source of examples for dictionary making or development of SKELL.
The Team
Throughout the years, some researchers have left the group and others have joined it, so the languages for which the project is currently developed are Dutch, Estonian, Slovene, and Brazilian Portuguese.
Current members:
- Tanara Zingano Kuhn – project leader, Research Centre for General and Applied Linguistics at University of Coimbra (CELGA-ILTEC), Portugal
- Ana R. Luís, Research Centre for General and Applied Linguistics at University of Coimbra (CELGA-ILTEC), Portugal
- Carole Tiberius, Dutch Language Institute, Netherlands
- Iztok Kosem, Centre for Language Resources and Technologies, University of Ljubljana, Slovenia
- Kristina Koppel, Institute of the Estonian Language, Estonia
- Rina Zviel Girshin, Ruppin Academic Center, Israel
- Špela Arhar Holdt, Centre for Language Resources and Technologies, University of Ljubljana, Slovenia
Former members:
- Andressa Rodrigues Gomide, Research Centre for General and Applied Linguistics at University of Coimbra (CELGA-ILTEC), Portugal
- Branislava Šandrih Todorović, University of Belgrade, Faculty of Philology, Serbia
- Danka Jokić, Serbia
- Peter Dekker, Dutch Language Institute, Netherlands & AI Lab, Vrije Universiteit Brussel, Belgium
- Ranka Stanković, Serbia
- Tanneke Schoonheim, Dutch Language Institute, Netherlands