Blog post written by Balázs Indig and Tamás Váradi; edited by Darja Fišer and Jakob Lenardič
The e-magyar toolchain was developed in 2016 as a major collaborative effort across the Hungarian community. The rationale for it was based on a clear vision of an open, modular, extendable and easy-to-use pipeline for Hungarian, which was suitable for non-specialists and developers alike. There existed pipelines created especially for Hungarian (e.g. the Hun* tools or Magyarlánc), and state-of-the art pipelines (e.g. StanfordNLP and UDPipe) also support Hungarian. However, they cannot fulfill the desired functions of modularity, extendability and user-friendliness. For example, improving the existing methods and annotations on different levels of processing were extremely tedious, which prematurely cut almost every attempt of natural improvement.
Therefore, the development of e-magyar started by collecting and integrating the best-practices and good features of the existing modules and pipelines while implementing the features that the community missed the most. The first version was integrated into the GATE framework.
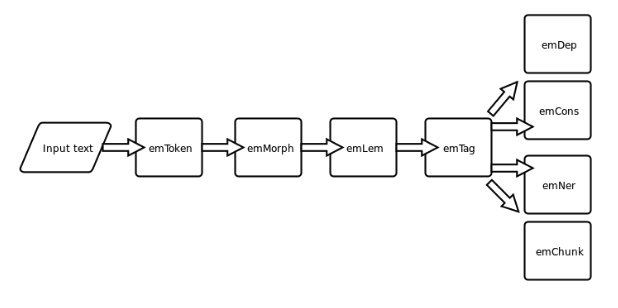
The toolchain consists of the following tools (see Figure 1 for the general architecture):
- emToken, a rule-based tokenizer which adds Unicode handling and detokenization to its ancestor Huntoken;
- emMorph, a rule-based morphological analyzer based on Helsinki Finite State Transducer, the flagship tool within e-magyar which integrates all previous efforts (including the commercial tool HUMOR) into a new, open-source tool for Hungarian;
- emPOS, a statistical POS-tagger derived form HunPOS which is an improved version of the TnT tagger,
- emDEP, a dependency parser and emCONS a constituent parser taken directly from Magyarlánc,
- emNER, a named entity recogniser based on the HUNtag3 framework,
- emChunk, a NP recogniser based on the HUNtag3 framework.
 ž
ž
Figure 1: the architecture of the e-magyar toolchain
To further improve efficiency and user-friendliness of e-magyar, the whole architecture was given a thorough overhaul in which the GATE framework was replaced with an inter-module communication framework that follows the toolbox philosophy. The new architecture makes e-magyar not only a truly modular, easy-to-use and extendable toolchain, but one that can be transformed into a webservice and a Python library in no time as well. To illustrate the modularity and enhanced flexibility of the system, many new modules have already become part of the toolchain, providing alternative options to existing modules. For example, the well-known spellchecker and stemmer Hunspell presents an alternative to emMorph and the three UDPipe modules - tokenizer, POS-tagger, dependency parser - can be selected in preference to emToken, emPOS and emDEP. To see emMorph in action, see this demo, displaying the analysis of the word bokraim ‘my shrubs’.
The e-magyar toolchain was developed to suit non-technical users as well. They can use the drag-and-drop Text Parser webservice which accepts short texts and outputs their analysed version to the selected level of detail (see Figure 2). In addition, a more light-weight web option, a web service of emMorph, (showing the morphological analysis of individual words) was also set up to enable linguists to check the analyses of particular words during their annotation work.

Figure 2: dependency parsing in the Text Parser webservice
Click here to read more about Tour de CLARIN